Apache Kafka로 실시간 데이터 흐름 만들기: 현업에서 바로 쓰는 파이프라인 구축 팁
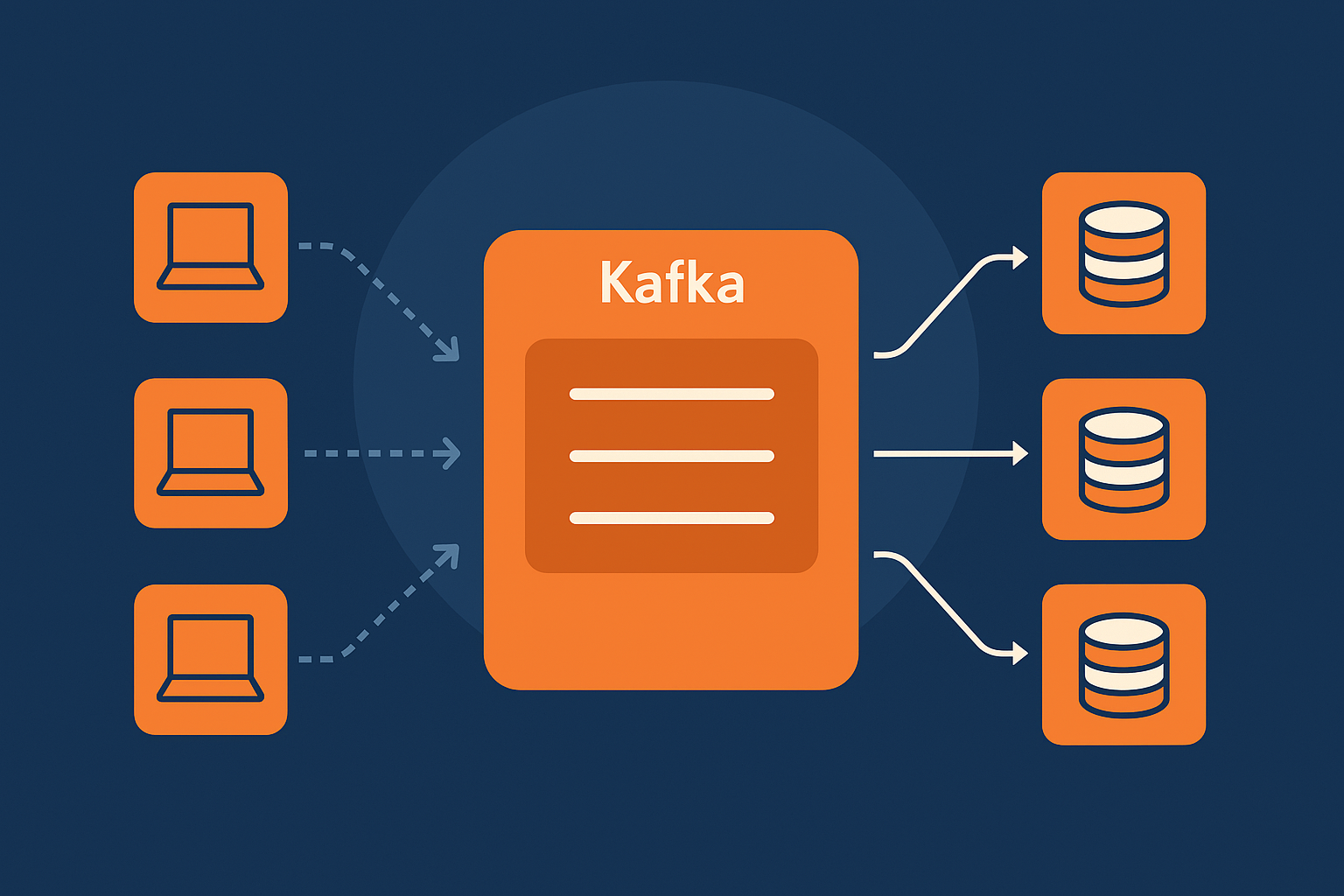
1. Apache Kafka란 도대체 무엇인가요?
Apache Kafka는 처음 들으면 뭔가 어려워 보이지만, 사실 알고 보면 ‘실시간 데이터의 고속도로’ 같은 존재입니다. 원래는 LinkedIn에서 내부용으로 만들었던 건데, 오픈소스로 공개되면서 지금은 대기업부터 스타트업까지 다들 사용하는 실시간 데이터 처리의 표준 솔루션으로 자리 잡았습니다. Kafka의 핵심 개념은 Publish-Subscribe 메시징 시스템인데요, 쉽게 말해 ‘누가 데이터를 보내고(Publish), 누가 그걸 구독해서 받아보느냐(Subscribe)’의 구조라고 보시면 됩니다. 이걸 통해 수많은 시스템 간에 데이터를 빠르게 전달할 수 있고, 각 컴포넌트가 독립적으로 동작할 수 있도록 도와주죠. 특히 금융, IoT, 전자상거래 같은 곳에서는 데이터가 실시간으로 흐르지 않으면 안 되는 경우가 많기 때문에 Kafka는 정말 큰 힘을 발휘합니다. 데이터를 한 번만 처리하고 끝나는 게 아니라, 여러 시스템에서 동시에 재사용하거나 분석하기 위해서도 Kafka는 정말 훌륭한 선택입니다.
2. Kafka의 아키텍처, 이렇게 생겼습니다
Kafka를 이해하려면 아키텍처를 한 번쯤 짚고 넘어가야 합니다. Kafka는 기본적으로 Producer, Broker, Topic, Consumer 네 가지 주요 구성 요소로 이뤄져 있습니다. Producer는 데이터를 생성해서 Kafka로 보내는 역할을 하고요, Consumer는 그 데이터를 구독해서 가져가는 역할을 합니다. Topic은 말 그대로 데이터가 모이는 채널이라고 생각하시면 됩니다. 예를 들어 ‘주문정보’, ‘로그정보’, ‘센서데이터’ 같은 종류별로 나눠 저장할 수 있죠. 이 Topic을 Kafka Broker가 중간에서 관리하고 전달해주는 겁니다. Broker는 데이터의 흐름을 관리하는 교통경찰 같은 역할을 한다고 보면 이해가 쉬우실 겁니다. 게다가 Kafka는 분산 시스템이라서 Broker가 여러 대 있어도 안정적으로 작동하고, 데이터가 많아져도 쉽게 확장할 수 있다는 장점이 있습니다.
3. 데이터 파이프라인이 왜 필요한가요?
실시간 데이터 파이프라인이 왜 중요한지 궁금하신 분들 많으실 텐데요. 예를 들어 쇼핑몰에서 고객이 주문을 하면, 그 정보가 재고 시스템, 결제 시스템, 배송 시스템, 통계 시스템 등 여러 곳으로 동시에 흘러가야 하지 않겠습니까? 이걸 수동으로 연결하거나 순차적으로 처리하면 시간도 오래 걸리고 실수가 발생할 수 있습니다. 바로 이럴 때 Kafka 기반의 실시간 파이프라인이 등장합니다. Kafka를 사용하면 데이터를 한 번만 Publish해도 여러 Consumer가 동시에 데이터를 받아볼 수 있어서, 각각의 시스템이 실시간으로 반응할 수 있게 됩니다. 마치 하나의 방송국에서 방송을 내보내면 수많은 TV가 동시에 수신하는 것과 비슷한 개념이라고 보시면 됩니다. 이 덕분에 기업들은 의사결정을 더 빠르게 내릴 수 있고, 고객에게도 더 신속한 서비스를 제공할 수 있죠.
4. Kafka Connect로 외부 시스템과 연결하세요
Kafka 혼자만 잘났다고 끝이 아닙니다. Kafka는 외부 시스템과의 연결을 쉽게 하기 위해 Kafka Connect라는 기능도 제공합니다. 데이터베이스, 파일 시스템, 클라우드 저장소, Elasticsearch, Hadoop 등 다양한 외부 시스템과 Kafka를 연결해주는 역할을 하죠. 예를 들어 MySQL에 저장된 데이터를 Kafka로 실시간으로 가져오거나, Kafka에서 받은 데이터를 바로 Amazon S3에 저장하는 것도 가능합니다. 이런 작업을 개발자가 코드로 일일이 구현하면 시간이 오래 걸리겠지만, Kafka Connect를 사용하면 플러그인 형태로 설정만 하면 바로 동작하니까 훨씬 효율적입니다. 특히 데이터 흐름을 자동화하고 싶으신 분들에게는 필수적인 도구라고 말씀드릴 수 있습니다.
5. Kafka Streams로 실시간 데이터 처리하기
Kafka는 단순히 데이터를 주고받는 데서 그치지 않습니다. 실시간 데이터 분석까지도 가능합니다. 그때 사용하는 도구가 바로 Kafka Streams입니다. 이건 Kafka 전용으로 만들어진 스트림 처리 라이브러리인데요, 실시간으로 들어오는 데이터를 필터링하거나 집계하거나, 변환하거나, 심지어 다른 Topic으로 재전송하는 작업도 할 수 있습니다. 기존에 Apache Storm이나 Spark Streaming을 써야 했던 작업들을 훨씬 가볍게 처리할 수 있죠. 게다가 Java나 Scala로 개발할 수 있어서 기존 시스템과의 연동도 편리하고요. Kafka Streams는 마치 데이터가 강물처럼 흘러갈 때, 중간중간 댐을 만들고, 수로를 바꾸고, 흐름을 조절하는 댐 관리자 같은 역할이라고 할 수 있겠습니다.
6. 실시간 알림 시스템에 Kafka를 적용해보세요
Kafka를 실시간 알림 시스템에 적용하면 어떤 장점이 있을까요? 예를 들어 은행 앱에서 계좌에 돈이 입금되었을 때, 고객에게 알림을 보내야 하죠. 이때 Kafka를 사용하면, 입금 데이터가 들어오자마자 Kafka Topic에 저장되고, 알림 시스템이 해당 Topic을 구독하면서 즉시 고객에게 메시지를 전송할 수 있습니다. 실시간성이 중요한 금융, 보안, 커머스 분야에서는 이처럼 빠른 반응이 필수입니다. Kafka 덕분에 기존 시스템을 손대지 않고도 새로운 기능을 쉽게 붙일 수 있다는 것도 큰 장점이죠. 알림 외에도 실시간 로그 분석, 모니터링 시스템과도 찰떡궁합입니다.
7. 데이터 유실 걱정? Kafka는 걱정 없습니다
실시간 데이터라고 하면 다들 “혹시 데이터 날아가는 거 아니야?” 하고 걱정하시는 분들 많으신데요. Kafka는 그런 걱정을 덜어주는 설계를 가지고 있습니다. Kafka는 데이터를 디스크에 저장하고, 원하는 기간 동안 유지할 수 있게 해줍니다. 게다가 Replication 기능이 있어서 하나의 Broker에 문제가 생기더라도 다른 Broker에서 데이터를 복구할 수 있습니다. 또한, ACK 설정을 통해 데이터를 정확히 한 번만 처리하는 것도 가능하고, 필요하다면 최소 한 번 이상 처리하거나, 적어도 한 번 처리하는 구조도 가능합니다. 이런 유연함 덕분에 Kafka는 실시간성과 신뢰성을 모두 잡은 시스템이라고 볼 수 있죠.
8. Kafka의 확장성, 이 정도면 괴물급입니다
Kafka는 **수평 확장성(Horizontal Scalability)**이 뛰어난 시스템입니다. 데이터가 많아져도 Broker를 추가하기만 하면 되니, 거의 무제한으로 확장이 가능합니다. Partition이라는 개념을 통해 Topic을 나누고, 각각의 Partition이 다른 서버에 분산돼 저장되기 때문에 성능 저하 없이 안정적으로 처리할 수 있는 겁니다. 실제로 Netflix, Uber, Airbnb 같은 글로벌 기업들도 Kafka를 통해 엄청난 양의 데이터를 실시간으로 처리하고 있습니다. Kafka는 단순한 메시징 시스템을 넘어서, 대규모 데이터 플랫폼의 핵심 인프라로 자리 잡았다고 보셔도 무방합니다.
9. Kafka를 이용한 마이크로서비스 통합
최근 많은 기업들이 마이크로서비스 아키텍처로 전환하면서, 시스템 간 통신에 Kafka를 사용하는 사례가 늘고 있습니다. 전통적인 REST API 방식은 요청-응답 구조라서 시스템 간 결합도가 높아지기 쉬운데요, Kafka는 비동기 메시징 방식이라 각 서비스가 독립적으로 동작할 수 있습니다. 주문 서비스가 Kafka에 메시지를 보내면, 배송 서비스, 결제 서비스, 재고 서비스가 각자 필요한 메시지만 골라 받아서 처리하는 식이죠. 이 덕분에 시스템 간의 유연성이 높아지고, 장애가 발생해도 전체 시스템이 멈추지 않고 계속 동작할 수 있습니다. Kafka는 마치 각 서비스 사이를 잇는 매끄러운 윤활유 같은 역할을 해주는 셈입니다.
10. Kafka와 함께라면 미래도 준비할 수 있습니다
Kafka는 단순한 데이터 처리 도구가 아니라, 기업의 디지털 전환을 가속화하는 핵심 기술입니다. 실시간 분석, 이벤트 기반 아키텍처, 인공지능 학습 데이터 스트림까지, 다양한 최신 기술과도 완벽하게 통합됩니다. 특히 Event Sourcing이나 CQRS(Command Query Responsibility Segregation) 패턴을 적용할 때도 Kafka는 아주 강력한 기반이 되어줍니다. 데이터가 끊임없이 흐르는 시대에, Kafka는 기업이 ‘데이터 중심 사고’를 할 수 있도록 도와주는 핵심 도구입니다. 처음엔 조금 어려워 보일 수 있지만, 한 번 익숙해지면 그 효율성과 유연성에 깜짝 놀라시게 될 겁니다. Kafka와 함께라면, 미래의 데이터 흐름도 충분히 감당할 수 있습니다.
결론: Kafka는 더 이상 선택이 아니라 필수입니다
Kafka는 단순히 데이터를 전달하는 도구가 아닙니다. 실시간 데이터 흐름을 설계하고, 각 시스템을 유기적으로 연결하며, 기업 전체의 데이터 생태계를 구성할 수 있는 강력한 실시간 데이터 플랫폼입니다. 처음에는 진입 장벽이 있을 수 있지만, 한 번 익히고 나면 복잡했던 데이터 파이프라인이 하나의 강줄기처럼 자연스럽게 흐르게 됩니다. 디지털 시대에 데이터는 곧 경쟁력입니다. Kafka를 통해 데이터의 속도와 정확성, 유연성을 확보하신다면, 그 자체가 미래를 준비하는 가장 강력한 무기가 될 것입니다.
자주 묻는 질문 (FAQs)
Q1. Kafka를 처음 배우려면 어떤 순서로 접근하는 게 좋을까요?
A. 먼저 Kafka의 기본 개념과 아키텍처를 이해하시고, 간단한 로컬 클러스터를 구축해보는 것이 좋습니다. 그 다음으로 Producer와 Consumer 개발을 경험해보시면 빠르게 익숙해질 수 있습니다.
Q2. Kafka는 어떤 언어로 개발할 수 있나요?
A. Kafka 클라이언트는 Java 기반이지만, Python, Go, .NET, Node.js 등 다양한 언어로도 개발할 수 있도록 클라이언트 라이브러리가 제공됩니다.
Q3. Kafka와 RabbitMQ는 어떤 차이가 있나요?
A. RabbitMQ는 전통적인 메시지 큐 시스템으로, 짧은 지연 시간과 요청-응답 구조에 적합합니다. Kafka는 대용량 데이터를 저장하고 스트리밍 처리에 적합한 구조로 설계되어 있습니다.
Q4. Kafka 운영 시 주의할 점은 무엇인가요?
A. Broker 간의 데이터 동기화, 디스크 사용량, Topic/Partition 설계 등을 신중히 관리해야 합니다. 특히 장애 복구 설정과 모니터링 시스템은 필수입니다.
Q5. Kafka만으로 ETL 시스템을 대체할 수 있을까요?
A. 경우에 따라 가능합니다. Kafka Streams나 Kafka Connect를 잘 활용하면, 전통적인 ETL 작업도 Kafka 기반으로 재구성할 수 있습니다. 다만 복잡한 데이터 변환에는 별도의 처리 엔진이 필요할 수도 있습니다.





