코드 품질과 협업을 높이는 리뷰의 기술과 문화 이야기
코드 리뷰, 들어보셨나요? 요즘 개발 현장에선 거의 필수 과정이 되었죠. 하지만 단순히 ‘코드 한 번 봐 주세요’에서 끝나는 게 아니라, 코드 리뷰 자체가 조직 문화의 핵심으로 자리 잡고 있습니다. 그렇다면 왜 코드 리뷰가 중요한지, 그리고 좋은 코드 리뷰를 위해서는 어떻게 해야 하는지 함께 알아볼까요? 이 글이 여러분에게 실질적인 도움과 인사이트가 되길 바랍니다. 왜 코드 리뷰…

코드 리뷰, 들어보셨나요? 요즘 개발 현장에선 거의 필수 과정이 되었죠. 하지만 단순히 ‘코드 한 번 봐 주세요’에서 끝나는 게 아니라, 코드 리뷰 자체가 조직 문화의 핵심으로 자리 잡고 있습니다. 그렇다면 왜 코드 리뷰가 중요한지, 그리고 좋은 코드 리뷰를 위해서는 어떻게 해야 하는지 함께 알아볼까요? 이 글이 여러분에게 실질적인 도움과 인사이트가 되길 바랍니다. 왜 코드 리뷰…
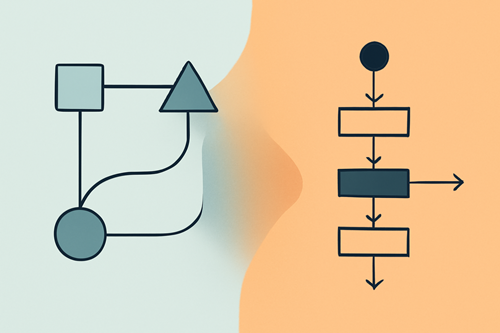
1. 함수형 프로그래밍이란? 복잡함 속의 아름다움 함수형 프로그래밍을 한마디로 요약한다면, ‘수학적 함수처럼 동작하는 프로그래밍 방식’이라고 할 수 있습니다. ‘함수’라는 단어에서 알 수 있듯, 입력값이 같으면 언제나 같은 출력을 내놓는 순수함수(pure function)가 핵심입니다. 이런 특성 때문에 함수형 코드는 마치 복잡한 수학 공식처럼 명확하고, 한 번 짜놓은 함수가 여기저기에서 재사용되기 좋아 코드의 재활용성과 유지보수성이 아주 뛰어납니다. 함수형…

1. 싱글턴 패턴: 하나뿐인 나만의 인스턴스, 꼭 필요한 순간에! 소프트웨어 개발 현장에서 가장 많이 마주치는 패턴을 꼽으라면, 단연 싱글턴 패턴이 있습니다. 싱글턴 패턴이란 애플리케이션 내에서 단 하나의 인스턴스만 생성되게 보장하고, 어디에서든 이 인스턴스에 접근할 수 있도록 하는 디자인 패턴입니다. 데이터베이스 커넥션 풀, 설정 관리 객체, 혹은 시스템 로그 기록기 등 이미 존재하는 자원을 여러 번…
Redis는 어떻게 동작할까요? Redis가 인메모리 데이터베이스로 유명한 이유는, 데이터를 빠르게 읽고 쓸 수 있는 구조에 있습니다. 모든 데이터가 메모리에 저장되기 때문에 디스크 기반 데이터베이스보다 접근 속도가 월등히 빠르죠. 이처럼 빠른 속도는 어떤 방식으로 구현되는 걸까요? Redis는 데이터를 key-value 쌍으로 저장합니다. 즉, 각각의 데이터에 고유한 키를 부여하고, 해당 키에 값을 연결하는 식이죠. 이 데이터들은 내부적으로 ‘dict’라는…

LVM이란? 탄탄한 기반 위에서 시작하는 저장소 관리의 새로운 패러다임 리눅스에서 파일 시스템을 관리하다 보면 ‘저장 공간이 부족하다’는 경고 메시지에 마음이 심란했던 적이 있으실 겁니다. 특히 서버 환경에서는 예상치 못한 저장 공간 증가나 파티션 나누기 실수로 인해 큰 불편을 겪기도 하지요. 그런데 이런 고민을 한방에 해결해 줄 마법 같은 기술이 바로 LVM(Logical Volume Manager)입니다. LVM은 곧…

테스트 주도 개발(TDD)이란 무엇인가요? 소프트웨어 개발을 하면서 ‘테스트 주도 개발(TDD)’이라는 말을 한 번쯤은 들어보셨을 것입니다. TDD는 말 그대로 테스트를 먼저 작성하고 그다음 실제 코드를 작성하는 개발 방법론입니다. 즉, 개발자는 기능을 추가하거나 코드를 수정하기 전에 우선적으로 해당 기능이 제대로 동작하는지를 검증할 수 있는 테스트 코드를 먼저 만듭니다. 그리고 이 테스트를 통과할 수 있는 최소한의 코드를 작성하고,…

Java와 Kotlin: 무엇이 다를까요? Java와 Kotlin, 두 언어는 현대 안드로이드 개발 환경에서 빠질 수 없는 선택지입니다. 많은 개발팀이 Java에서 Kotlin으로 이동하는 이유는 무엇일까요? 단순히 새로운 기술이 좋아서만은 아닙니다. 두 언어는 서로 닮은 듯 다르지만, 개발 경험에는 분명한 차이가 있습니다. Java는 1995년 처음 공개된 이후 지금까지도 많은 애플리케이션에서 핵심 역할을 하고 있습니다. 안전성과 안정성에 중점을 둔…

1. 실시간 데이터 파이프라인이란? 오늘날 데이터의 흐름은 그야말로 ‘강물’처럼 빠르게 변하고 있습니다. 실시간으로 움직이는 수많은 데이터, 이를 모으고 가공하여 가치를 만들어내는 일이 기업의 경쟁력을 좌우하게 되었는데요. 축적되는 방대한 정보를 제때 가공하지 못하면, 마치 큰물을 원천에서 퍼다 쓰지 못하는 것처럼 귀중한 기회를 놓칠 수 있습니다. 바로 이럴 때 필요한 것이 ‘실시간 데이터 파이프라인’입니다. 이는 데이터를 실시간으로…

서론: 왜 OLAP 시스템이 주목받는가? 최근 데이터 활용이 기업 경쟁력 강화의 핵심으로 부상하면서, 대용량 데이터 분석을 위한 OLAP(Online Analytical Processing) 시스템에 대한 관심이 그 어느 때보다 높아졌습니다. 데이터가 늘어날수록 복잡한 쿼리와 빠른 응답 속도는 필수가 되었죠. 전통적인 데이터베이스만으론 이러한 요구를 충족하기 어렵기 때문에, OLAP 시스템이 대안으로 등장하고 있습니다. 그중에서도 ClickHouse는 속도와 확장성 면에서 주목받는 오픈소스…

서론: 소프트웨어 설계의 길, 그 이면에 숨어 있는 함정들 소프트웨어 개발을 하다 보면 누구나 효율적이고 아름다운 설계를 꿈꿉니다. 그래서 널리 알려진 디자인 패턴을 학습하고 적용하며, 그 노하우를 통해 더 나은 코드를 만들고자 노력하는데요. 그런데 혹시, ‘이렇게 하면 더 쉬울 것 같아서’, ‘그냥 빨리 끝내고 싶어서’, 혹은 ‘어쩔 수 없는 상황이라서’ 했던 선택들이 쌓이고 쌓이다 보면,…