ETL과 ELT, 무엇이 다른가요? 데이터 파이프라인 구축 가이드라인
1. ETL과 ELT는 똑같아 보여도, 실제론 흐름부터 다릅니다
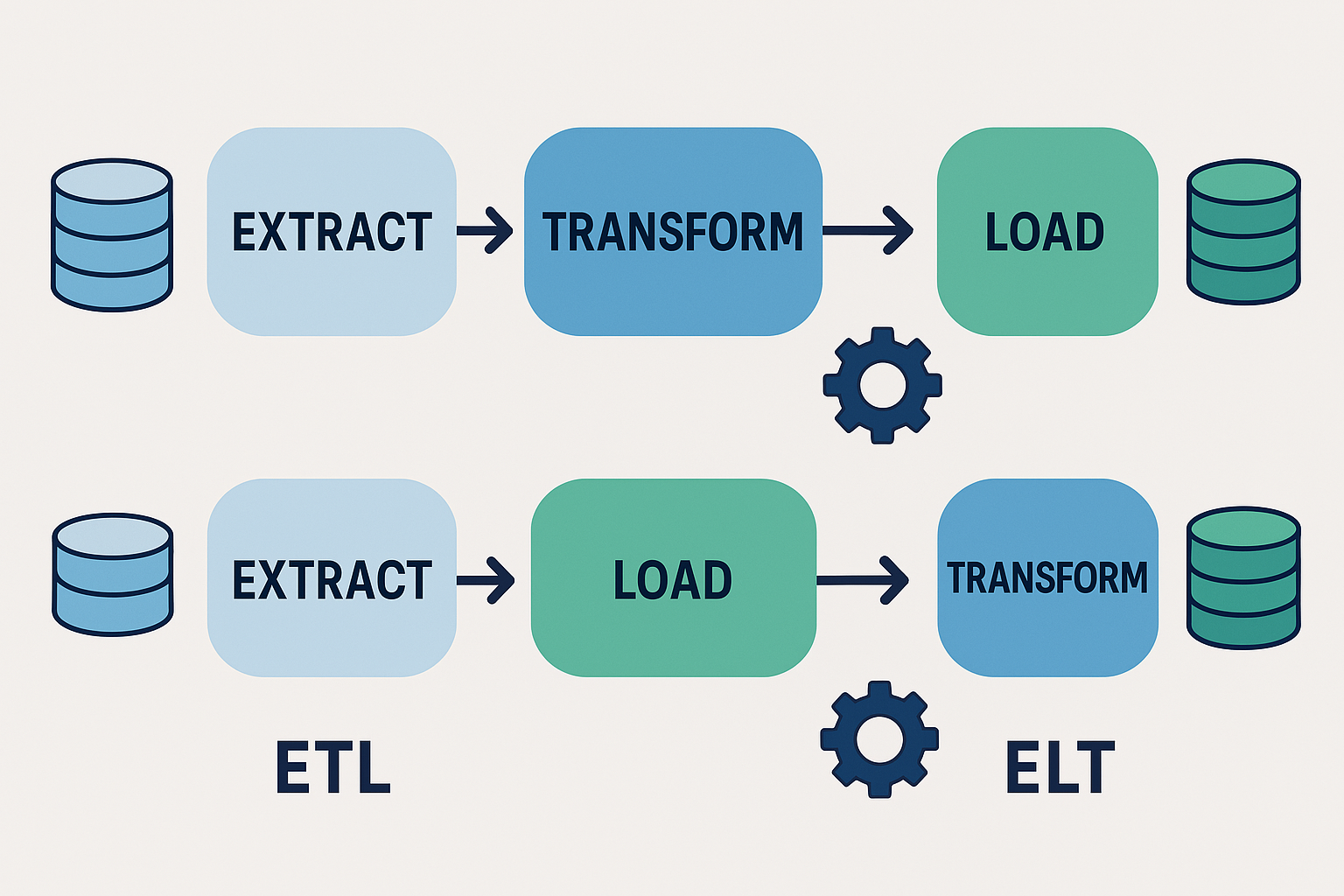
데이터 엔지니어링을 조금이라도 접해보신 분들이라면 ‘ETL’이라는 용어는 익숙하실 겁니다. 하지만 비슷하게 생긴 ‘ELT’라는 용어는 어쩌면 최근에야 눈에 띄셨을 수도 있겠네요. 이 둘은 데이터 처리에서 매우 핵심적인 개념이지만, 그 흐름 자체가 완전히 다릅니다. ETL은 Extract(추출) → Transform(변환) → Load(적재) 순으로 데이터를 처리하고요, ELT는 Extract(추출) → Load(적재) → Transform(변환) 순입니다. 순서만 바뀐 것처럼 보이지만, 이 변화가 데이터 아키텍처 전체를 흔들 정도로 중요하다는 점, 알고 계셨나요?
ETL 방식은 전통적인 데이터 웨어하우스 환경에서 주로 쓰였습니다. 예를 들어, 은행이나 보험사처럼 정형화된 데이터를 정해진 규칙으로 정제해서 분석하는 곳이죠. 여기서는 변환이 로딩 전에 이뤄져야 하니, 별도의 중간 서버나 ETL 툴이 필요했고, 이로 인해 복잡하고 느린 구조가 만들어졌습니다. 반면 ELT는 클라우드 기반의 데이터 레이크나 모던 웨어하우스를 중심으로 작동합니다. 데이터를 먼저 통째로 집어넣고, 그 안에서 SQL이나 Spark로 가공하는 형태입니다. 대용량 데이터를 빠르게 다루는 데 이보다 효율적인 방식은 없습니다. 즉, ETL은 ‘깔끔하게 정리해서 들여보내는 스타일’이라면, ELT는 ‘일단 다 들여놓고 내부에서 청소하는 스타일’이라고 비유할 수 있겠네요.
2. 전통적인 ETL의 장점과 한계, 그 속에 숨은 고민들
ETL 방식은 구조적이고 명확한 데이터 흐름을 추구합니다. 데이터의 추출부터 변환, 적재까지의 모든 과정을 통제할 수 있어 기업 내부 규제가 강한 곳에선 지금도 널리 쓰이고 있죠. 특히 데이터 품질이 중요한 금융, 의료, 제조업 분야에서는 ETL이 주는 ‘사전 정제된 안심’이 상당히 매력적입니다. 중간에 잘못된 값이 있으면 초기에 걸러내고, 변환 단계에서 오류를 방지하며, 로딩 전에 완전히 정돈된 데이터를 넘기니까요.
하지만 문제는 이 구조가 너무 ‘무겁다’는 데 있습니다. 새로운 데이터를 처리할 때마다 다시 추출하고, 다시 가공하고, 다시 적재해야 하니 민첩성이 떨어집니다. 무엇보다도, 실시간 스트리밍 데이터나 비정형 데이터에는 매우 취약하죠. 예전에는 하루에 한 번 배치로 데이터를 가져오면 충분했지만, 지금은 사용자가 웹사이트를 클릭할 때마다, 앱에서 행동할 때마다 데이터가 생성되고 있습니다. 이런 흐름을 따라가려면 ETL만으로는 역부족일 수밖에 없습니다.
3. ELT가 가져온 혁신, 그리고 그 속의 가능성
ELT 방식은 클라우드 기반의 확장성과 현대적 아키텍처 덕분에 점점 더 각광받고 있습니다. 특히 Snowflake, BigQuery, Redshift 같은 모던 데이터 웨어하우스와의 조합은 ELT의 가능성을 극대화하죠. 데이터를 일단 몽땅 넣은 후, SQL이나 Python 기반의 처리 로직으로 필요한 형태로 바꾸는 이 방식은 무척 유연하고 빠릅니다.
예를 들어, 마케터가 오늘 캠페인 데이터를 가져와 실시간으로 매출 흐름을 보고 싶다면, ETL로는 거의 불가능합니다. 하지만 ELT라면 데이터를 먼저 넣어두고, SQL 하나만 던져도 그 결과를 실시간으로 확인할 수 있습니다. 다시 말해, ELT는 ‘데이터 중심의 의사결정’을 할 수 있게 해주는 최고의 파트너가 되어줍니다. 물론 ELT도 단점이 있습니다. 너무 많은 데이터를 적재하면 비용이 증가할 수 있고, 데이터 품질이 낮은 경우엔 변환이 더 복잡해지기도 하죠. 하지만 이 모든 건 설계와 관리의 문제일 뿐, 기술 자체의 문제는 아닙니다.
4. 데이터 볼륨에 따라 달라지는 도구 선택 기준
ETL과 ELT 중 어떤 방식을 선택할지는 데이터의 볼륨과 복잡성에 따라 달라집니다. 예를 들어, 하루에 1만 건 이하의 정형 데이터를 처리하는 중소기업이라면 굳이 복잡한 ELT 플랫폼을 도입할 필요는 없습니다. 오히려 Talend나 Pentaho 같은 전통적인 ETL 툴이 더 효율적일 수도 있죠.
반면, 대기업처럼 수십 테라바이트 이상의 데이터를 다루고, 여러 출처에서 동시에 들어오는 로그와 트랜잭션 데이터를 실시간으로 처리해야 한다면, ELT가 훨씬 유리합니다. 특히 Airbyte, Fivetran 같은 ELT 기반의 데이터 파이프라인 툴은 자동화와 확장성이 뛰어나서 유지보수에도 강점을 보입니다. 중요한 건 툴보다 흐름이라는 점을 잊지 않으셔야 합니다. 아무리 좋은 도구도, 잘못된 구조 위에 얹히면 무용지물일 수 있으니까요.
5. ETL 도구의 대표주자들: Talend, Informatica, Apache NiFi
ETL 쪽에서 가장 많이 쓰이는 툴로는 Talend가 있습니다. 오픈소스 기반이라 중소기업도 쉽게 접근할 수 있고, 커넥터가 다양해서 어떤 데이터 소스든 연결할 수 있다는 장점이 있죠. 또 다른 대표주자 Informatica는 대기업들이 좋아하는 솔루션입니다. 가격이 비싼 대신, 보안이나 데이터 거버넌스 면에서는 매우 뛰어나니까요. Apache NiFi는 조금 색다른 방향으로, 플로우 기반의 GUI를 제공해 시각적으로 데이터 흐름을 설계할 수 있어 인기를 끌고 있습니다.
이러한 도구들은 ETL 프로세스를 체계적으로 관리할 수 있게 해주지만, 배포와 유지보수가 까다롭다는 단점도 있습니다. 특히 클라우드 환경으로 완전히 전환하려는 기업에는 적합하지 않을 수 있습니다. 다시 말해, 정형화된 조직에겐 ETL이 안정감을 주지만, 빠른 대응이 필요한 조직에겐 오히려 발목을 잡을 수 있다는 점, 꼭 기억하셔야 합니다.
6. ELT 도구의 핵심: Fivetran, Airbyte, dbt
ELT의 중심엔 ‘자동화’가 있습니다. 데이터를 가져와 바로 웨어하우스에 적재하고, 그 후 처리까지 알아서 해주는 ELT 툴은 빠르게 변화하는 비즈니스 환경에 적합하죠. 대표적인 툴로는 Fivetran이 있습니다. 다양한 커넥터와 안정적인 스케줄링 시스템 덕분에 많은 SaaS 기반 기업들이 애용하고 있습니다.
Airbyte는 오픈소스 기반으로, 원하는 데이터 소스를 자유롭게 커스터마이징할 수 있다는 점에서 개발자들에게 인기가 높습니다. 그리고 **dbt(Data Build Tool)**는 ELT 방식에서 가장 중요한 ‘변환’ 작업을 SQL로 모듈화해주는 도구입니다. dbt를 사용하면 SQL을 통해 테스트, 문서화, 재사용이 쉬운 데이터 모델을 만들 수 있어 협업에도 최적화되어 있죠. 즉, ELT의 진가는 dbt에서 시작된다고 해도 과언이 아닙니다.
7. 클라우드 데이터 웨어하우스와 ELT의 찰떡궁합
ELT가 각광받게 된 가장 큰 이유는 클라우드 웨어하우스의 발전 덕분입니다. Google BigQuery, Amazon Redshift, Snowflake 같은 플랫폼은 저장과 처리 능력이 압도적입니다. 과거에는 데이터를 저장하고 처리하는 데 제약이 많았지만, 지금은 클라우드에서 원하는 만큼 저장하고, 원하는 만큼 쿼리할 수 있죠.
이 덕분에 ELT는 예전보다 훨씬 간단하고 효율적인 흐름으로 진화할 수 있었습니다. 데이터를 그대로 로드하고, 웨어하우스 내부에서 처리하는 방식은 비용과 시간 모두를 절감할 수 있으니까요. 물론 쿼리 비용이나 저장소 과금은 신경 써야 하지만, 잘만 설계하면 오히려 기존 방식보다 훨씬 경제적입니다. 클라우드 웨어하우스와 ELT는 ‘스마트폰과 앱’ 같은 관계입니다. 단독으로는 매력 없지만, 함께할 때 진짜 힘을 발휘하죠.
8. 실시간 데이터 분석과 스트리밍 환경에서의 선택은?
요즘 데이터는 실시간으로 쏟아지고 있습니다. 사용자 클릭, IoT 센서, 금융 거래… 모두가 실시간으로 움직이죠. 이럴 땐 단순한 배치 ETL로는 절대 따라갈 수 없습니다. Kafka, Apache Flink 같은 스트리밍 기술과 연결된 ELT 기반의 실시간 처리 구조가 필요합니다. ELT는 데이터를 바로 받아 저장하고, 그 안에서 분석하므로 실시간 대시보드, 알림 시스템과 찰떡궁합을 이룹니다.
특히 모니터링이나 알림이 중요한 산업군이라면 ELT와 스트리밍을 함께 쓰는 아키텍처가 답입니다. 물론 구축 난이도는 높지만, 이점을 보면 도전할 가치가 충분하죠. 데이터를 ‘늦게’ 보는 것과 ‘바로’ 보는 것, 이 둘 사이의 비즈니스 결과는 하늘과 땅 차이입니다.
9. 데이터 거버넌스와 보안은 어떻게 다를까요?
많은 분들이 ELT가 자유롭고 빠르다 보니, 데이터 거버넌스나 보안에는 취약할 거라 생각하시곤 합니다. 하지만 꼭 그렇진 않습니다. dbt와 같은 도구는 변환 작업마다 문서화, 테스트, 감사 로그를 자동화할 수 있고, 클라우드 웨어하우스 자체도 접근 제어와 로깅 기능이 뛰어납니다.
반대로 ETL은 ‘사전에 처리’하니 안정적인 거 아니냐는 의견도 있지만, 사실 중간 서버가 많고 복잡한 흐름이 많을수록 취약점이 생길 확률도 올라갑니다. 결국, 보안은 방식의 문제가 아니라 설계와 관리의 문제입니다. 어떤 방식을 쓰든, ‘누가’, ‘어떻게’ 관리하느냐가 핵심입니다.
10. 결론: ETL과 ELT, 정답은 없고 ‘상황’이 답입니다
지금까지 ETL과 ELT의 구조, 흐름, 도구, 장단점에 대해 살펴봤습니다. 요약하자면, ETL은 안정성과 품질을 우선하는 구조화된 환경에 적합하고, ELT는 속도와 확장성을 중시하는 현대적인 환경에 어울립니다. 둘 중 어떤 방식이 ‘정답’은 없습니다. 데이터의 특성, 조직의 문화, 예산, 기술 수준, 궁극적인 비즈니스 목표에 따라 달라지기 때문입니다.
그래서 중요한 건 트렌드가 아닙니다. ‘우리 회사에 맞는 데이터 흐름이 무엇인가’를 고민하고, ‘현재의 문제를 해결할 수 있는 도구가 무엇인가’를 판단하는 일입니다. 데이터는 단순히 쌓는 것이 아니라, 비즈니스 인사이트로 연결되어야 진짜 가치가 생긴다는 점, 잊지 마시기 바랍니다.
자주 묻는 질문 (FAQs)
Q1. ELT 방식은 모든 기업에 적합한가요?
아닙니다. 실시간 분석이 필요하거나 대규모 데이터를 다루는 기업에 적합하며, 전통적인 환경에선 오히려 부담이 될 수 있습니다.
Q2. dbt는 꼭 ELT 환경에서만 써야 하나요?
주로 ELT 환경에서 쓰이지만, ETL에서도 변환 로직 관리용으로 활용할 수 있습니다. 다만 웨어하우스 기반의 처리에 최적화되어 있습니다.
Q3. 클라우드가 필수인가요? 온프레미스에서도 ELT를 쓸 수 있나요?
이론상 가능하지만, ELT는 클라우드 웨어하우스의 확장성과 비용 구조를 활용하는 것이 핵심이라 온프레미스에선 비효율적일 수 있습니다.
Q4. ETL과 ELT를 함께 쓸 수도 있나요?
네, 하이브리드 구조로 병행하는 경우도 많습니다. 초기 정제는 ETL, 이후 분석은 ELT로 분리해 효율을 극대화하기도 합니다.
Q5. 어떤 도구를 선택해야 할지 모르겠습니다. 어떻게 시작하면 좋을까요?
현재 데이터 흐름을 문서화하고, 처리량, 실시간성, 예산, 팀 역량을 기준으로 평가해보세요. 필요시 PoC(파일럿 프로젝트)로 먼저 테스트해보시는 것도 좋은 방법입니다.